日記/2019-2
| << | 2019-2 | >> | ||||
| S | M | T | W | T | F | S |
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | ||
2019-2-28
Googleカレンダーにプロ野球の日程をインポートするためスクレイピング・続
一昨日、Googleカレンダーにプロ野球の日程をインポートする方法を紹介したが、Pythonのことをよく知らない私は、世の中にはpandasという便利なモノがあることを知らなかった。これを用いてスクリプトを書き直してみたら、かなりすっきり書くことができて満足。でも、まあ、これまた習作ということで。
#!/usr/bin/python3
#coding: utf-8
#scrapingnpb2.py
import sys
import re
import datetime
import pandas
import pprint
print("Subject, Start Date, Start Time, End Date, End Time, Description, Location")
months = ['03', '04', '05', '06', '07', '08', '09']
# 0, 1, 2, 3, 4, 5
#(0, '3/29(金)', 'DeNA - 中日', '横\u3000浜 18:30', nan, nan)
for month in months:
url = "http://npb.jp/games/2019/schedule_" + month + "_detail.html"
tb = pandas.io.html.read_html(url)
for row in tb[0].itertuples(name=None):
card = ''
md = re.sub(r'(.*)', '', row[1])
ymd = '2019/' + md
sttm = ''
entm = ''
place = ''
if row[2] == row[2]:
card = re.sub(' - ', '対', row[2])
if row[3] == row[3]:
place_time = row[3].split(' ')
if len(place_time) > 1:
(sthr, stmn) = place_time[1].split(':')
(mon, day) = md.split('/')
start = datetime.datetime(2019, int(mon), int(day), int(sthr), int(stmn), 0)
delta = datetime.timedelta(minutes=200)
end = start + delta
sttm = start.strftime("%H:%M:%S")
entm = end.strftime("%H:%M:%S")
place = re.sub(r'\s+', '', place_time[0])
else:
sttm = '18:00:00'
entm = '21:20:00'
place = place_time[0]
if len(sys.argv) > 1:
m = re.search(sys.argv[1], card)
if m:
print(f"{card}, {ymd}, {sttm}, {ymd}, {entm}, {card}, {place}")
elif card != '':
print(f"{card}, {ymd}, {sttm}, {ymd}, {entm}, {card}, {place}")
使い方は「./scrapingnpb2.py」、もしくは「./scrapingnpb2.py 阪神」という風に球団名を与える。何も与えないとすべての日程が、球団名を与えるとその球団のみの日程が出力される。
出力結果をcsvファイルとして保存し、GoogleカレンダーにインポートすればOK。
阪神タイガースの公式サイトの試合日程のページはtableタグが使われていないため、安直にpandasは使えなかった。残念。
2019-2-27
Googleカレンダーに阪神タイガースの試合日程をインポートするためスクレイピング
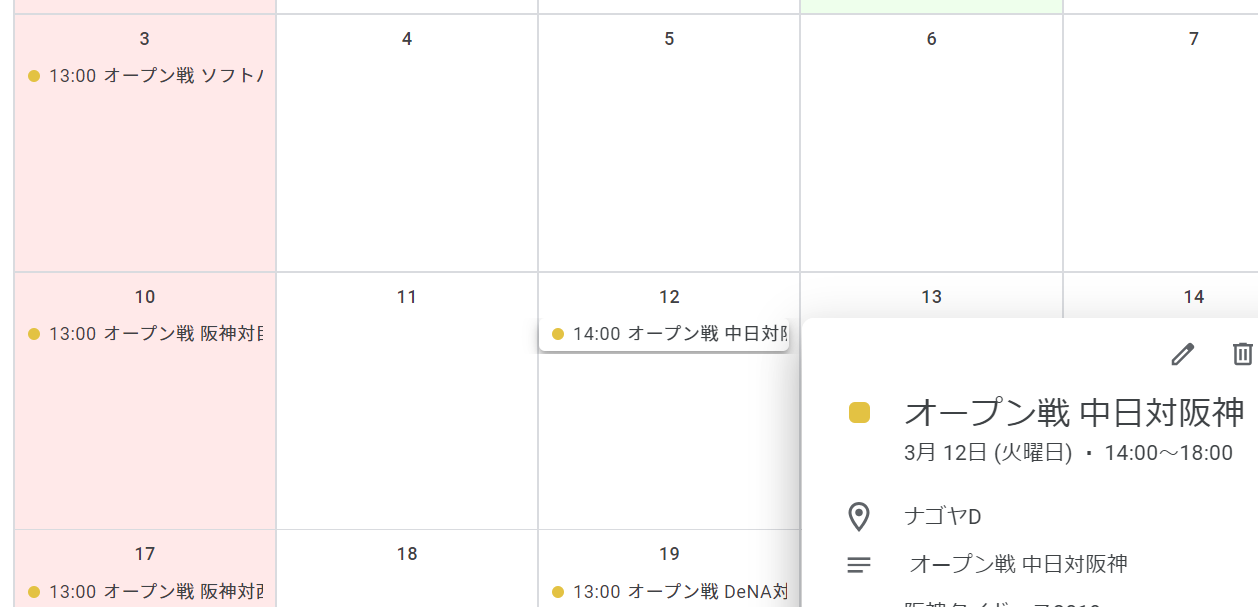
昨日、Googleカレンダーにプロ野球の日程をインポートする方法を紹介したが、スクレイピングの情報源の日本野球機構の試合日程のページには、公式戦の日程しか載っていない。
私は阪神ファンなのだが、すでに始まっているオープン戦の情報もぜひ載せたいと思い、阪神タイガースの公式サイトの試合日程のページをスクレイピングして(スクレイピングのしやすさから、ケータイ向けのページを参照している)、試合日程の情報をゲットし、これをGoogleカレンダーに表示してみた。
スクレイピングするスクリプトは勉強中のPythonで書いてみた。これまた習作ということで。
#!/usr/bin/python3
#coding: utf-8
#scrapingtigers.py
import re
import datetime
import urllib.request
import pprint
from bs4 import BeautifulSoup
data = {}
team = {
't':'阪神',
's':'ヤクルト',
'd':'中日',
'h':'ソフトバンク',
'e':'楽天',
'f':'日本ハム',
'l':'西武',
'db':'DeNA',
'm':'ロッテ',
'bs':'オリックス',
'g':'巨人',
'c':'広島',
}
head = "Subject, Start Date, Start Time, End Date, End Time, Description, Location"
print(head)
month_days = {'03':'31', '04':'30', '05':'31', '06':'30', '07':'31', '08':'31', '09':'30'}
for month in month_days.keys():
data.setdefault(month, {})
for day in range(int(month_days[month])):
data[month].setdefault(day + 1, {})
data[month][day + 1].setdefault('date', '2019/' + month + "/" + ('0' + str(day + 1))[-2:])
for month in month_days.keys():
html = urllib.request.urlopen("https://m.hanshintigers.jp/game/schedule/2019/" + month + ".html")
soup = BeautifulSoup(html, features="lxml")
day = 1
for tag in soup.select('li.box_right.gameinfo'):
text = re.sub(' +', '', tag.text)
info = text.split("\n")
if len(info) > 3:
if info[1] == '\xa0':
info[1] = ''
data[month][day].setdefault('gameinfo', info[1])
data[month][day].setdefault('start', info[2])
data[month][day].setdefault('stadium', info[3])
if re.match('オールスターゲーム', info[2]):
data[month][day]['gameinfo'] = info[2]
data[month][day]['start'] = '18:00'
text = str(tag.div)
if text:
m = re.match(r'^.*"nologo">(\w+)<.*$', text, flags=(re.MULTILINE|re.DOTALL))
if m:
gameinfo = m.group(1)
data[month][day].setdefault('gameinfo', gameinfo)
m = re.match(r'^.*"logo_left (\w+)">.*$', text, flags=(re.MULTILINE|re.DOTALL))
if m:
team1 = m.group(1)
data[month][day].setdefault('team1', team[team1])
m = re.match(r'^.*"logo_right (\w+)">.*$', text, flags=(re.MULTILINE|re.DOTALL))
if m:
team2 = m.group(1)
data[month][day].setdefault('team2', team[team2])
day += 1
for month in month_days.keys():
for day in data[month].keys():
if data[month][day].get('start'):
m = re.match(r'(\d+):(\d+)', data[month][day]['start'])
if m:
sthr = m.group(1)
stmn = m.group(2)
start = datetime.datetime(2019, int(month), int(day), int(sthr), int(stmn), 0)
delta = datetime.timedelta(hours=4)
end = start + delta
sttm = start.strftime("%H:%M:%S")
entm = end.strftime("%H:%M:%S")
summary = ''
if data[month][day]['gameinfo']:
summary = data[month][day]['gameinfo'] + " "
if not re.match('オールスターゲーム', data[month][day]['gameinfo']):
summary += data[month][day]['team1'] + "対" + data[month][day]['team2']
#head = "Subject, Start Date, Start Time, End Date, End Time, Description, Location"
print(f"{summary}, {data[month][day]['date']}, {sttm}, {data[month][day]['date']}, {entm}, {summary}, {data[month][day]['stadium']}")
使い方は「./scrapingtigers.py」と実行するだけ。
3月からの情報をスクレイピングしている(2月のイベントはすでに終わってしまったと言うこともあるが、2月には、起亜タイガース相手の練習試合とか、紅白戦とか、イレギュラーな処理が必要なイベントがあり、それらが無視できるとうれしいということもある)。
また、オープン戦、交流戦の場合は、イベント名の頭にそれぞれ「オープン戦」「交流戦」と表示される。
さらには、試合開始時刻が不明だとイベントとして登録できないため、オールスターゲームの試合開始は勝手に18時とした。
出力結果をcsvファイルとして保存し、GoogleカレンダーにインポートすればOK。
2019-2-26
Googleカレンダーにプロ野球の日程をインポートするためスクレイピング

Googleカレンダーには、「関心のあるカレンダーを探す」から追加できるように、日本のプロ野球の日程があらかじめ用意されている(参考)。
が、球団名が英語表記だったりしてどうも気に入らない。
そこで、日本野球機構の試合日程のページをスクレイピングして、試合日程の情報をゲットし、これをGoogleカレンダーに表示してみた。
スクレイピングするスクリプトは勉強中のPythonで書いてみた。習作ということで。
#!/usr/bin/python3
#coding: utf-8
#scrapingnpb.py
import sys
import re
import datetime
import urllib.request
import pprint
from bs4 import BeautifulSoup
data = {}
head = "Subject, Start Date, Start Time, End Date, End Time, Description, Location"
print(head)
month_days = {'03':'31', '04':'30', '05':'31', '06':'30', '07':'31', '08':'31', '09':'30', '10':'30'}
for month in month_days.keys():
data.setdefault(month, {})
for day in range(int(month_days[month])):
data[month].setdefault(day + 1, {})
data[month][day + 1].setdefault('date', '2019/' + month + "/" + ('0' + str(day + 1))[-2:])
data[month][day + 1].setdefault('id_date', 'date' + month + ('0' + str(day + 1))[-2:])
for month in month_days.keys():
html = urllib.request.urlopen("http://npb.jp/games/2019/schedule_" + month + "_detail.html")
soup = BeautifulSoup(html, features="lxml")
for day in data[month].keys():
for n in range(6):
data[month][day].setdefault(n, {})
num = 0
for tr in soup.find_all("tr", attrs={"id": data[month][day]['id_date']}):
div = tr.select_one("td>div.place")
if div:
p = re.sub(r'\s+', '', div.text)
data[month][day][num].setdefault('place', p)
div = tr.select_one("td>div.time")
if div:
data[month][day][num].setdefault('time', div.text)
div = tr.select_one("td>div.team1")
if div:
data[month][day][num].setdefault('team1', div.text)
div = tr.select_one("td>div.team2")
if div:
data[month][day][num].setdefault('team2', div.text)
div = tr.select_one("td>div.commentLong")
if div:
data[month][day][num].setdefault('comment', div.text)
num += 1
for month in month_days.keys():
for day in data[month].keys():
for num in range(6):
if data[month][day][num].get('time'):
m = re.match(r'(\d+):(\d+)', data[month][day][num]['time'])
if m:
sthr = m.group(1)
stmn = m.group(2)
start = datetime.datetime(2019, int(month), int(day), int(sthr), int(stmn), 0)
delta = datetime.timedelta(hours=4)
end = start + delta
sttm = start.strftime("%H:%M:%S")
entm = end.strftime("%H:%M:%S")
summary = ''
if data[month][day][num].get('comment'):
summary = data[month][day][num]['comment']
else:
summary = data[month][day][num]['team1'] + "対" + data[month][day][num]['team2']
#head = "Subject, Start Date, Start Time, End Date, End Time, Description, Location"
if len(sys.argv) > 1:
m = re.search(sys.argv[1], summary)
if m:
print(f"{summary}, {data[month][day]['date']}, {sttm}, {data[month][day]['date']}, {entm}, {summary}, {data[month][day][num]['place']}")
else:
print(f"{summary}, {data[month][day]['date']}, {sttm}, {data[month][day]['date']}, {entm}, {summary}, {data[month][day][num]['place']}")
使い方は「./scrapingnpb.py」、もしくは「./scrapingnpb.py 阪神」という風に球団名を与える。何も与えないとすべての日程が、球団名を与えるとその球団のみの日程が出力される。
出力結果をcsvファイルとして保存し、GoogleカレンダーにインポートすればOK。