日記/2020-6-2より前の5日分
2020-4-22
RakutenBooksSearch プラグイン
昨年(2019年)Amazonアソシエイト・プログラムのPA-API(Product Advertising API)の利用規約が変更され、PA-APIのリンクを介した売り上げが発生しないサイトではPA-APIが使えなくなりました。AmazonSearch プラグインではPA-APIを叩いているのですが、うちみたいな売り上げなんか全くない弱小ウェブサイトではすぐに使えなくなってしまいました。
それから一年以上ほっといたわけですが、このところやることもなくてヒマなので、PA-APIに代わり、楽天ブックス総合検索APIを用いた商品検索の結果を表示するFreeStyleWikiのプラグインを作成してみました。
インストール
- 楽天ウェブサービスの新規アプリ登録のページから、新規アプリを登録し、applicationId、affiliateIdを取得します。
- 以下のファイルをダウンロードします。
- rakutensearch.zip(276)
- RakutenBooksSearch.pmの86行目にapplicationIdを、87行目にaffiliateIdをそれぞれ設定します。
- plugin以下にインストールします。
- なお、楽天ブックス総合検索APIはHTTPSであるため、LWP::UserAgentがアクセスするためにはLWP::Protocol::httpsが必要となることに注意が必要。幸いこのサイトがホストされているさくらインターネットのマシンにはあらかじめこのモジュールがインストールされていたため、新たにインストールするなどの対応は必要なかった。
使い方
{{rakutenbookssearch 東野圭吾,b,10,m}}
- 「東野圭吾」は検索語で必須のパラメータ。
- 「b」は商品のジャンルで以下の種類がある。省略時はa。
| パラメータ | ジャンル |
|---|---|
| a | すべて |
| b | Book |
| c | CD |
| d | DVD |
| s | Software |
| f | Foreign Book |
| g | Game |
| m | Magazine |
- 「10」は結果の数で省略可能。省略時は1。最大値は30。
- 「m」は書影のサイズで、s、m、lから選べる。省略時はs。
 | |
| クスノキの女神 | |
| 実業之日本社 | |
| 東野 圭吾 | |
| 楽天 Amazon | |
 | |
| ブラック・ショーマンと名もなき町の殺人 | |
| 光文社 | |
| 東野圭吾 | |
| 楽天 Amazon | |
 | |
| ブラック・ショーマンと覚醒する女たち | |
| 光文社 | |
| 東野圭吾 | |
| 楽天 Amazon | |
 | |
| 白鳥とコウモリ(下) | |
| 幻冬舎 | |
| 東野 圭吾 | |
| 楽天 Amazon | |
 | |
| 白鳥とコウモリ(上) | |
| 幻冬舎 | |
| 東野 圭吾 | |
| 楽天 Amazon | |
 | |
| 白鳥とコウモリ(上)(下)セット | |
| 幻冬舎 | |
| 東野 圭吾 | |
| 楽天 Amazon | |
 | |
| 時ひらく | |
| 文藝春秋 | |
| 辻村 深月/伊坂 幸太郎/阿川 佐和子/恩田 陸/柚木 麻子/東野 圭吾 | |
| 楽天 Amazon | |
 | |
| クスノキの番人 | |
| 実業之日本社 | |
| 東野 圭吾 | |
| 楽天 Amazon | |
 | |
| 白銀ジャック 新装版 | |
| 実業之日本社 | |
| 東野 圭吾 | |
| 楽天 Amazon | |
 | |
| 白夜行 | |
| 集英社 | |
| 東野 圭吾 | |
| 楽天 Amazon |
補足
- 楽天だけでなく、ついでにAmazonへのリンクもつけてみたが、
13桁のISBNやJANコードから無理矢理検索した結果のページへのリンクになっている。JANコードは無理矢理検索した結果のページだが、13桁のISBNは10桁に変換してすっきりしたURLへのリンクにした。これで許してください。 - プラグインの出力全体を <div class="rakutensearch">〜</div> でくるんであります。テーブルを組んで表示していますので、枠線がうるさく感じる場合にはCSSで非表示にしてください。
div.rakutensearch table, div.rakutensearch th, div.rakutensearch td, div.rakutensearch img {
border-style:none;
}
- 当初は、楽天商品検索APIを使って、楽天市場の商品を検索するプラグインも作ろうと思ってたのですが、楽天ブックスだけで十分な感じがしてやめてしまいました。気が向いたら作るかもしれません。
- PA-APIが使えない本サイトでは、AmazonSearch プラグインを書き換えて、内部でRakutenBooksSearch プラグインを呼ぶようにしてみました。これで既存のページに記載されているAmazonSearch プラグインの部分でもそれっぽい表示がなされるようになるはず。
2020-3-22
2020年の桜







2020/03/22(日)撮影
2019-3-9
漱石と隻腕の学生・続続
「漱石山脈 現代日本の礎を築いた『師弟愛』」を読了(以下「漱石山脈」)。
この本の中で、「漱石と隻腕の学生」で取り上げた、漱石が東京帝国大学で講師をしていた時に起きた「懐手事件」について触れられていた。
私見によれば、「懐手事件」には、その場に居合わせた二人がそれぞれ唱えている、森田草平説、金子健二説の二つの説がある。
森田説は、事件の発生日は明治38年11月10日ごろで、隻腕の学生(後年、魚住惇吉だということが明らかになる)に対してそうと知らずに小言を言ってしまった漱石が、恐縮して「僕も毎日無い智慧を絞つて講義をしてゐるんだから、君もたまには無い腕でも出したらよからう」という一言を漏らした、というもの。
対して金子説では、事件が起きたのは森田説より一年ほど前の明治37年12月1日。懐手の学生に注意した漱石は、その学生が隻腕であることを知ると、何も言わずそのまま教室から出て行ったことになっている。
金子説は、それが記された金子の著書「人間漱石」の、件の学生の着物の色柄や表情など、細部に至る詳細な記載が信憑性の高さを感じさせ、そのため、漱石の一言は本当はなかった、後年誰かによって創作されたものだ、という話の根拠となっている。
しかしながら、漱石自身が明治38年11月13日に野村伝四に出した私信で「近頃失敬の至」として事件に触れ、最後の一言も記している。事件から一年以上経っている私信でそれを「近頃」のことだとするのか、という疑問から、この葉書は金子説の信憑性を揺るがすものとなっている。
結局、森田説、金子説のいずれが本当のことなのかわからない、というのが、「漱石と隻腕の学生」に記した結論であった。
「漱石山脈」で、筆者の長尾剛は、森田説と金子説の折衷案とも言える説を唱えている(ように私には思える)。
長尾は、基本的には金子説に沿いながらも、
魚住の席と金子の席が離れていたため漱石が無言だったように見えただけであろう
として、最後の一言はあった、としている。
そして、漱石が事件から一年後に出した私信で、事件が「近頃」のことだとしたのは、
魚住の件は、少なくとも一年近く、漱石にとって生々しい「恥ずべき記憶」として続いていたようである。
との理由だと解釈している。
まあ、この辺がうまい落とし所かな、と私も思う(声が聞こえないくらい離れた席で、なぜ着物の色柄や学生の表情までわかったのか、という疑問は残るが)。
事件に関して、このような「それらしい解釈」がなされた書物が世に出た、ということは、なんだか喜ばしい、と自分勝手に思う次第。
2019-2-28
Googleカレンダーにプロ野球の日程をインポートするためスクレイピング・続
一昨日、Googleカレンダーにプロ野球の日程をインポートする方法を紹介したが、Pythonのことをよく知らない私は、世の中にはpandasという便利なモノがあることを知らなかった。これを用いてスクリプトを書き直してみたら、かなりすっきり書くことができて満足。でも、まあ、これまた習作ということで。
#!/usr/bin/python3
#coding: utf-8
#scrapingnpb2.py
import sys
import re
import datetime
import pandas
import pprint
print("Subject, Start Date, Start Time, End Date, End Time, Description, Location")
months = ['03', '04', '05', '06', '07', '08', '09']
# 0, 1, 2, 3, 4, 5
#(0, '3/29(金)', 'DeNA - 中日', '横\u3000浜 18:30', nan, nan)
for month in months:
url = "http://npb.jp/games/2019/schedule_" + month + "_detail.html"
tb = pandas.io.html.read_html(url)
for row in tb[0].itertuples(name=None):
card = ''
md = re.sub(r'(.*)', '', row[1])
ymd = '2019/' + md
sttm = ''
entm = ''
place = ''
if row[2] == row[2]:
card = re.sub(' - ', '対', row[2])
if row[3] == row[3]:
place_time = row[3].split(' ')
if len(place_time) > 1:
(sthr, stmn) = place_time[1].split(':')
(mon, day) = md.split('/')
start = datetime.datetime(2019, int(mon), int(day), int(sthr), int(stmn), 0)
delta = datetime.timedelta(minutes=200)
end = start + delta
sttm = start.strftime("%H:%M:%S")
entm = end.strftime("%H:%M:%S")
place = re.sub(r'\s+', '', place_time[0])
else:
sttm = '18:00:00'
entm = '21:20:00'
place = place_time[0]
if len(sys.argv) > 1:
m = re.search(sys.argv[1], card)
if m:
print(f"{card}, {ymd}, {sttm}, {ymd}, {entm}, {card}, {place}")
elif card != '':
print(f"{card}, {ymd}, {sttm}, {ymd}, {entm}, {card}, {place}")
使い方は「./scrapingnpb2.py」、もしくは「./scrapingnpb2.py 阪神」という風に球団名を与える。何も与えないとすべての日程が、球団名を与えるとその球団のみの日程が出力される。
出力結果をcsvファイルとして保存し、GoogleカレンダーにインポートすればOK。
阪神タイガースの公式サイトの試合日程のページはtableタグが使われていないため、安直にpandasは使えなかった。残念。
2019-2-27
Googleカレンダーに阪神タイガースの試合日程をインポートするためスクレイピング
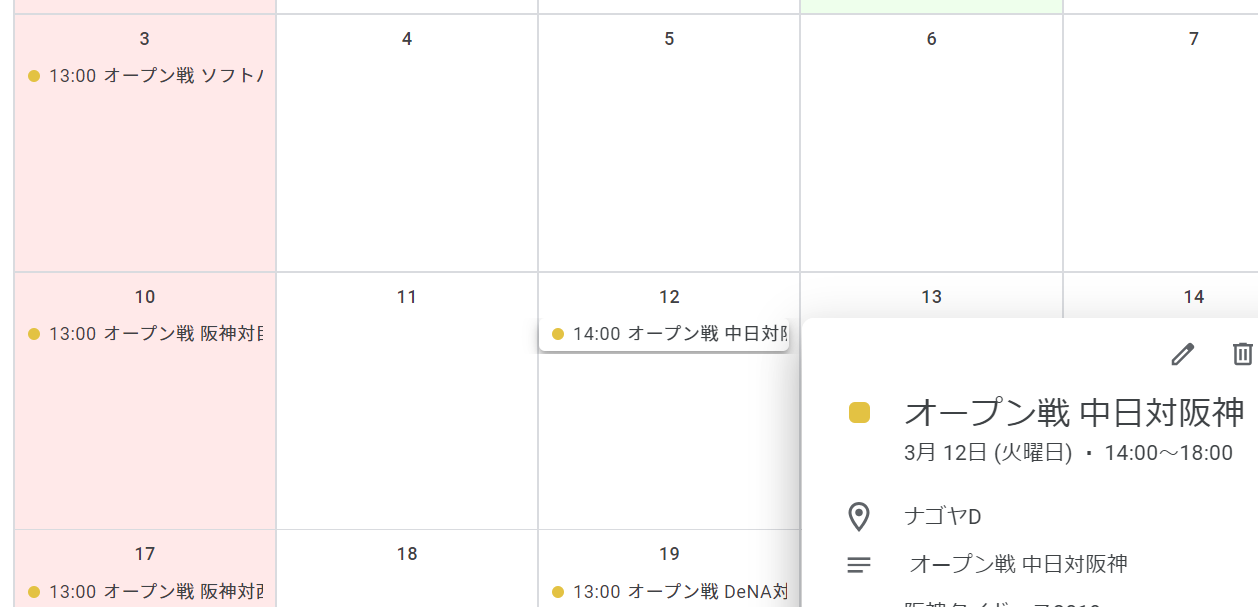
昨日、Googleカレンダーにプロ野球の日程をインポートする方法を紹介したが、スクレイピングの情報源の日本野球機構の試合日程のページには、公式戦の日程しか載っていない。
私は阪神ファンなのだが、すでに始まっているオープン戦の情報もぜひ載せたいと思い、阪神タイガースの公式サイトの試合日程のページをスクレイピングして(スクレイピングのしやすさから、ケータイ向けのページを参照している)、試合日程の情報をゲットし、これをGoogleカレンダーに表示してみた。
スクレイピングするスクリプトは勉強中のPythonで書いてみた。これまた習作ということで。
#!/usr/bin/python3
#coding: utf-8
#scrapingtigers.py
import re
import datetime
import urllib.request
import pprint
from bs4 import BeautifulSoup
data = {}
team = {
't':'阪神',
's':'ヤクルト',
'd':'中日',
'h':'ソフトバンク',
'e':'楽天',
'f':'日本ハム',
'l':'西武',
'db':'DeNA',
'm':'ロッテ',
'bs':'オリックス',
'g':'巨人',
'c':'広島',
}
head = "Subject, Start Date, Start Time, End Date, End Time, Description, Location"
print(head)
month_days = {'03':'31', '04':'30', '05':'31', '06':'30', '07':'31', '08':'31', '09':'30'}
for month in month_days.keys():
data.setdefault(month, {})
for day in range(int(month_days[month])):
data[month].setdefault(day + 1, {})
data[month][day + 1].setdefault('date', '2019/' + month + "/" + ('0' + str(day + 1))[-2:])
for month in month_days.keys():
html = urllib.request.urlopen("https://m.hanshintigers.jp/game/schedule/2019/" + month + ".html")
soup = BeautifulSoup(html, features="lxml")
day = 1
for tag in soup.select('li.box_right.gameinfo'):
text = re.sub(' +', '', tag.text)
info = text.split("\n")
if len(info) > 3:
if info[1] == '\xa0':
info[1] = ''
data[month][day].setdefault('gameinfo', info[1])
data[month][day].setdefault('start', info[2])
data[month][day].setdefault('stadium', info[3])
if re.match('オールスターゲーム', info[2]):
data[month][day]['gameinfo'] = info[2]
data[month][day]['start'] = '18:00'
text = str(tag.div)
if text:
m = re.match(r'^.*"nologo">(\w+)<.*$', text, flags=(re.MULTILINE|re.DOTALL))
if m:
gameinfo = m.group(1)
data[month][day].setdefault('gameinfo', gameinfo)
m = re.match(r'^.*"logo_left (\w+)">.*$', text, flags=(re.MULTILINE|re.DOTALL))
if m:
team1 = m.group(1)
data[month][day].setdefault('team1', team[team1])
m = re.match(r'^.*"logo_right (\w+)">.*$', text, flags=(re.MULTILINE|re.DOTALL))
if m:
team2 = m.group(1)
data[month][day].setdefault('team2', team[team2])
day += 1
for month in month_days.keys():
for day in data[month].keys():
if data[month][day].get('start'):
m = re.match(r'(\d+):(\d+)', data[month][day]['start'])
if m:
sthr = m.group(1)
stmn = m.group(2)
start = datetime.datetime(2019, int(month), int(day), int(sthr), int(stmn), 0)
delta = datetime.timedelta(hours=4)
end = start + delta
sttm = start.strftime("%H:%M:%S")
entm = end.strftime("%H:%M:%S")
summary = ''
if data[month][day]['gameinfo']:
summary = data[month][day]['gameinfo'] + " "
if not re.match('オールスターゲーム', data[month][day]['gameinfo']):
summary += data[month][day]['team1'] + "対" + data[month][day]['team2']
#head = "Subject, Start Date, Start Time, End Date, End Time, Description, Location"
print(f"{summary}, {data[month][day]['date']}, {sttm}, {data[month][day]['date']}, {entm}, {summary}, {data[month][day]['stadium']}")
使い方は「./scrapingtigers.py」と実行するだけ。
3月からの情報をスクレイピングしている(2月のイベントはすでに終わってしまったと言うこともあるが、2月には、起亜タイガース相手の練習試合とか、紅白戦とか、イレギュラーな処理が必要なイベントがあり、それらが無視できるとうれしいということもある)。
また、オープン戦、交流戦の場合は、イベント名の頭にそれぞれ「オープン戦」「交流戦」と表示される。
さらには、試合開始時刻が不明だとイベントとして登録できないため、オールスターゲームの試合開始は勝手に18時とした。
出力結果をcsvファイルとして保存し、GoogleカレンダーにインポートすればOK。